
문제
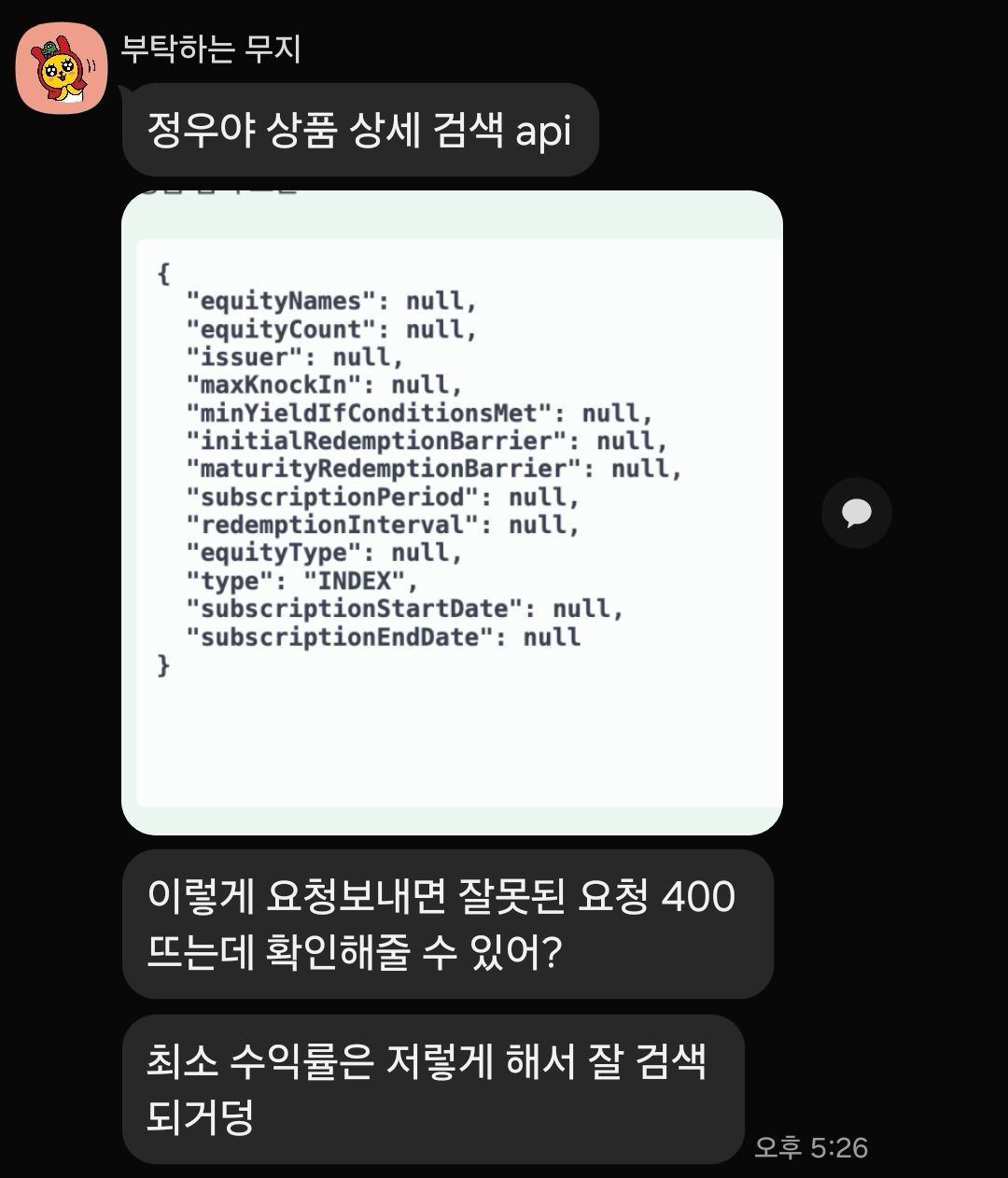

소마 프로젝트를 진행하던 도중, 팀원으로부터 오류 제보를 받았습니다.
저희 서비스에서 제공하고 있는 상품 상세 검색 기능에서 종목 유형에 대한 세부 검색 요청시,
이에 해당하는 상품들을 받아오지 못하는 오류가 발생하는 문제였습니다.
잠시 저희 서비스에 대해서 간략하게 설명 드리자면,
주요 여러 증권사에서 발행하고 있는 금융 파생 상품 중에 하나인 ELS(Equity Linked Securities, 주가연계증권) 상품을
통합하고 데이터 분석 기법 및 AI를 활용한 중립적인 분석 정보를 제공하는 서비스입니다.
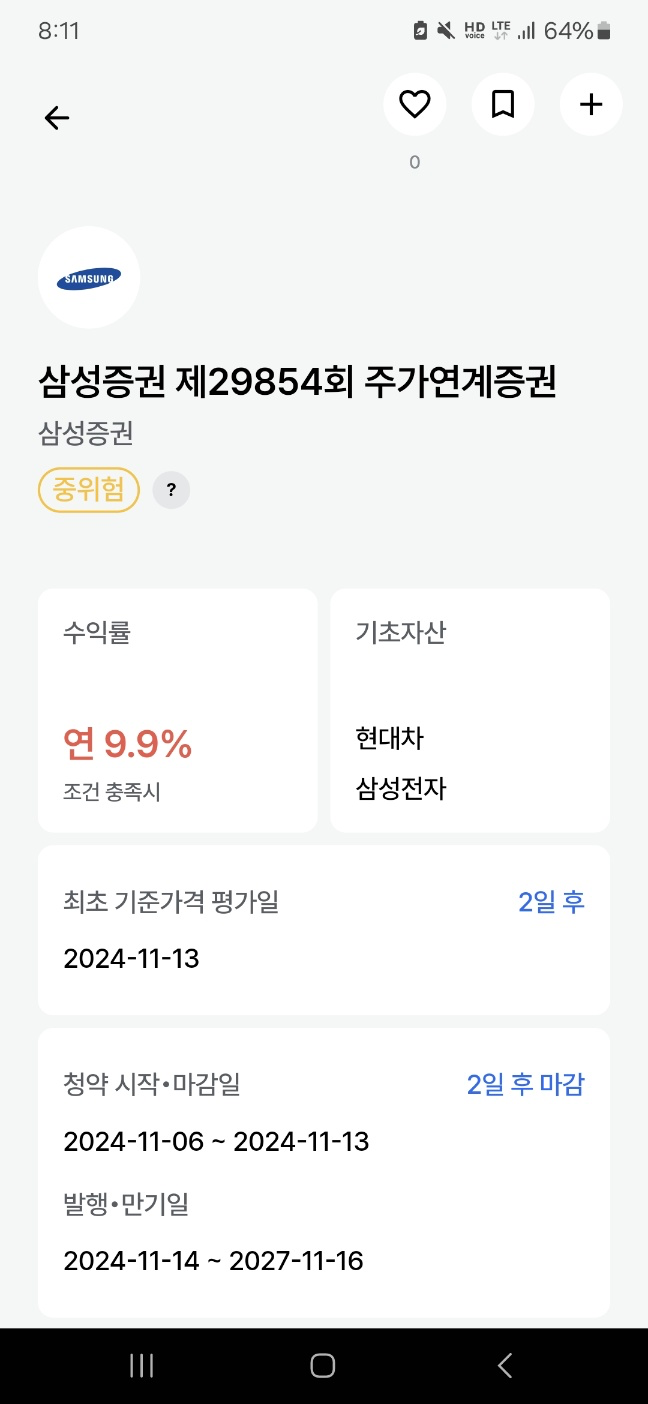
아래와 같이 각 상품마다 기초자산들이 존재하는데
왼쪽 사진의 S&P500, KOSPI, HSCEI와 같은 주가 지수형인 경우와,
오른쪽 사진과 같이 삼성전자, 현대차와 같은 단일 주식들로 이루어진 종목형,
주가 지수와 단일 주식이 섞여서 하나의 상품으로 이루어진 혼합형이 존재합니다.

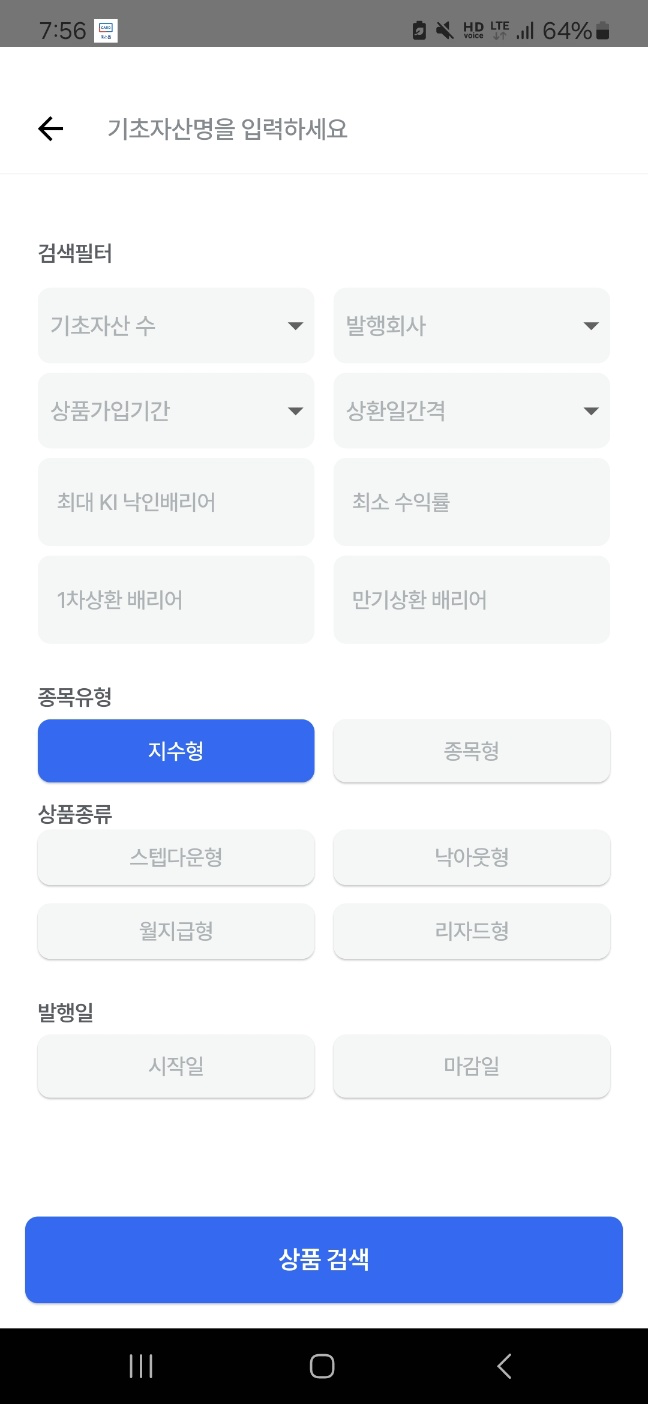
다시 본론으로 돌아와서,
아래와 같이 상품 상세 검색 기능에서 종목 유형을 지수형으로 선택하고 상품 검색을 진행했을 때
오른쪽 사진처럼 현재 청약 중인 상품들이 존재하지 않다고 보여주는 것을 확인할 수 있었습니다.

처음 오류를 마주했을 때, 평소에는 조건에 맞는 상품들이 잘 검색되었어서 상당히 당황스러웠습니다.
간헐적으로 이와 같은 오류가 발생하다가 어느 시점부터 계속 API 응답을 정상적으로 받아오지 못하는 것을 확인할 수 있었습니다.
원인
현재 상품 상세 검색은 SpringBoot 환경에서 QueryDSL의 동적 쿼리를 통한 조회를 수행하고 있었고,
해당 검색 API는 상품 서비스에서 동작하는 기능이기 때문에, 해당 서비스에 접근하여 에러 로그를 확인해보았더니
StackOverflowError가 발생하고 있었습니다.
ERROR 1 --- [product-service] [nio-7072-exec-4] ERROR [product-service,67307033ea0270505d459b5b52caad36,c479e1342b939756]c.w.e.global.error.ControllerAdvisor : Unexpected exception has occurred in controller advice: [id=8b1231e1-34d4-4030-bad9-4ccee0997bdb]
jakarta.servlet.ServletException: Handler dispatch failed: java.lang.StackOverflowError
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1104) ~[spring-webmvc-6.1.10.jar!/:6.1.10]
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:979) ~[spring-webmvc-6.1.10.jar!/:6.1.10]
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1014) ~[spring-webmvc-6.1.10.jar!/:6.1.10]
...
at org.apache.tomcat.util.threads.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1190) ~[tomcat-embed-core-10.1.25.jar!/:na]
at org.apache.tomcat.util.threads.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:659) ~[tomcat-embed-core-10.1.25.jar!/:na]
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:63) ~[tomcat-embed-core-10.1.25.jar!/:na]
at java.base/java.lang.Thread.run(Thread.java:833) ~[na:na]
Caused by: java.lang.StackOverflowError: null
at com.querydsl.jpa.JPAMapAccessVisitor.visit(JPAMapAccessVisitor.java:27) ~[querydsl-jpa-5.0.0-jakarta.jar!/:na]
at com.querydsl.core.types.OperationImpl.accept(OperationImpl.java:88) ~[querydsl-core-5.0.0.jar!/:na]
at com.querydsl.core.support.ReplaceVisitor.visit(ReplaceVisitor.java:161) ~[querydsl-core-5.0.0.jar!/:na]
StackOverflowError가 발생하는 대체적인 이유들이 존재합니다.
우선 JVM(Java Virtual Machine)에서 작성되는 모든 스레드에는 고유 스택 공간이 있습니다.
애플리케이션에 사용 가능한 전체 스택 크기는 시작 동안 판별되고, 해당 값은 포함할 수 있는 스레드 수를 판별하는데
순환참조로 인한 무한루프가 발생하거나,
스택이 다 소진될 때까지 메서드 내에서 메서드를 계속 호출하는 상황으로 인해
초과하게 된다면 해당 오류가 발생할 수 있습니다.
비교적 풍부한 자원을 가지고 있는 로컬 환경에 비해서
개발 서버는 AWS EC2의 t3.small(2CPU, RAM 2GB)인 작은 인스턴스 유형을 사용했기 때문에
이러한 StackOverflowError가 자주 발생했습니다.
그래서 개발 서버에 코드를 올리기 전까지 로컬에서 테스트를 했을 때는 아무 이상이 없어서
이러한 오류를 감지하지 못했었습니다. 심지어 nGrinder로 로컬 환경에서 성능 테스트를 했을 때도 오류가 발생하지 않아서...
당연히 잘되는줄...
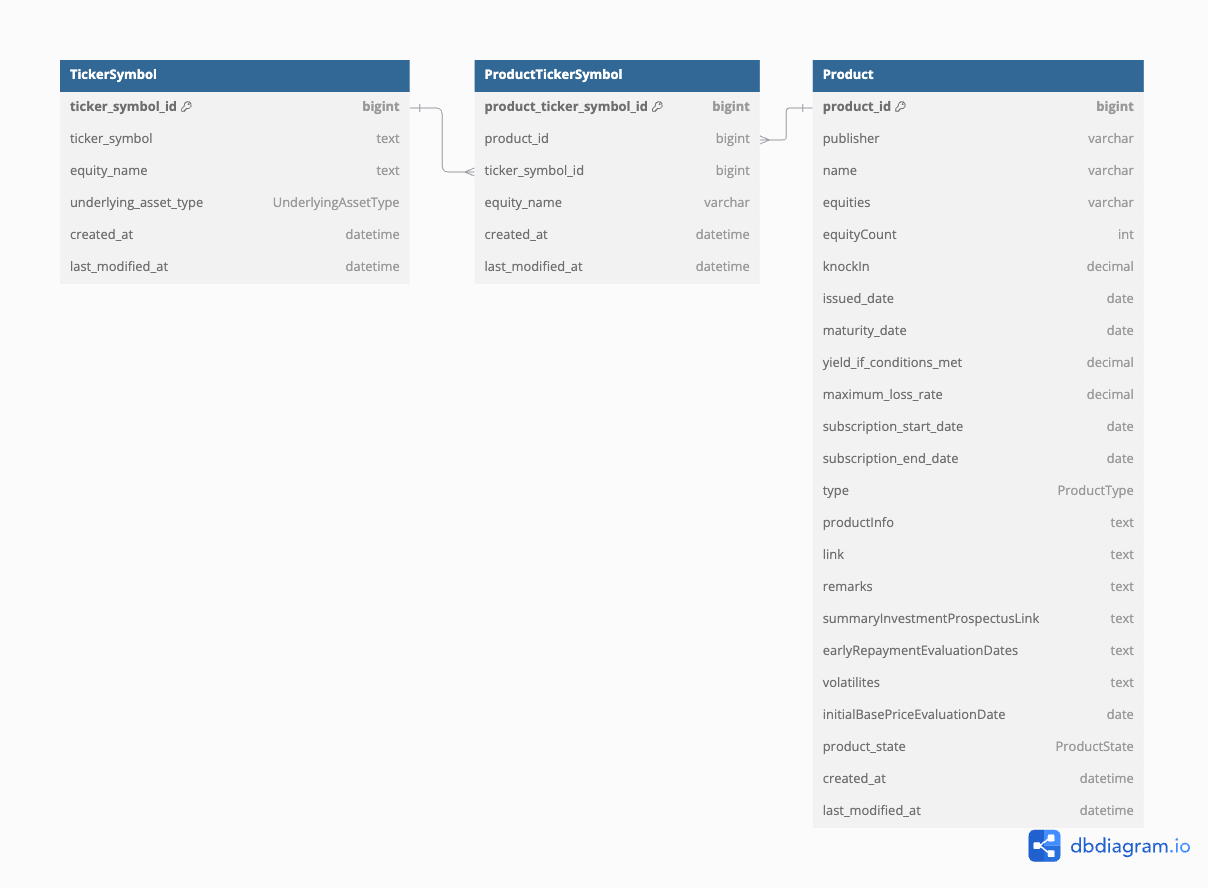
현재 Product와 TickerSymbol 그리고 중간 테이블인 ProductTickerSymbol은 아래와 같이 구성되어있습니다.
문제가 발생한 코드는 아래와 같습니다.
특히나 'type == UnderlyingAssetType.INDEX || type == UnderlyingAssetType.STOCK' 이 부분에 해당하는
if문 안의 쿼리문이 StackOverflowError를 발생시키는 코드로 추정되었습니다.
private BooleanExpression equityTypeEq(UnderlyingAssetType type) {
List<Long> result = new ArrayList<>();
if (type != null) {
if (type == UnderlyingAssetType.INDEX || type == UnderlyingAssetType.STOCK) {
List<Tuple> tmp = queryFactory
.select(productTickerSymbol.product.id, productTickerSymbol.product.id.count())
.from(productTickerSymbol)
.join(productTickerSymbol.tickerSymbol, tickerSymbol1)
.where(productTickerSymbol.tickerSymbol.underlyingAssetType.eq(type))
.groupBy(productTickerSymbol.product.id)
.fetch();
BooleanBuilder predicate = new BooleanBuilder();
for (Tuple tuple : tmp) {
Long productId = tuple.get(productTickerSymbol.product.id);
Long count = tuple.get(productTickerSymbol.product.id.count());
predicate.or(
product.id.eq(productId).and(product.equityCount.eq(count.intValue()))
);
}
result = queryFactory
.select(product.id)
.from(product)
.where(predicate)
.groupBy(product.id)
.fetch();
return product.id.in(result);
} else if (type.equals(UnderlyingAssetType.MIX)) {
result = queryFactory
.select(productTickerSymbol.product.id)
.from(productTickerSymbol)
.join(productTickerSymbol.tickerSymbol, tickerSymbol1)
.where(productTickerSymbol.tickerSymbol.underlyingAssetType.in(UnderlyingAssetType.STOCK, UnderlyingAssetType.INDEX))
.groupBy(productTickerSymbol.product.id)
.having(
productTickerSymbol.tickerSymbol.underlyingAssetType.countDistinct().eq(2L)
)
.fetch();
}
return product.id.in(result);
}
return null;
}
특히나 predicate.or() 부분이 가장 마음에 걸렸던게,
스택 메모리 크기는 JVM 설정에 따라 제한되는데 OR 조건이 많아 복잡한 쿼리가 생성되면,
애플리케이션이 스택 메모리를 많이 사용하게 되어 기본 JVM 스택 크기를 초과했던 것으로 생각이됩니다.
당시 개발 서버에 상품이 2500여개가 존재하였고,
그 중에서 주가지수형, 종목형, 혼합형의 비율이 전체를 10이라고 봤을 때
5.5 : 3.1 : 1.4의 비율로 구성되어 있는 형태로, 주가지수형이 가장 많았습니다.
그리고 각 종목에 해당하는 상품을 검색했을 때,
혼합형(MIX)은 else if로 따로 처리되는데 혼합형에 대해서 부하 테스트를 진행해도 오류가 발생하지 않았고
주가지수형(INDEX) 검색이 StackOverflowError가 가장 많이 발생했던 것을 봤을 때,
DB 안에 상품이 가장 많고 위 코드에서 predicate.or()로 인한 복잡한 쿼리 호출이
StackOverflowError가 발생하는 가장 요인이 되지 않았나라는 생각이 들었습니다.
해결
위 문제를 해결하기 위해서 계속 고민하다 보니
배치 서비스에서 매일 상품들을 받아올 때, 처음부터 각 상품에 해당하는 기초자산들이 주가지수형, 종목형, 혼합형인지 파악하여
상품 엔티티에 필드를 추가해서 파악한 내용을 저장해놓는 방식이 가장 이상적일 것이라는 생각이 들었습니다.
원래는 문제가 되었던 쿼리문과 같이, 여러 조인문을 사용해서 검색 기능을 수행해도 큰 무리가 없을거 같았으나
검색 기능인 만큼, 서비스를 사용하는 사용자 입장에서 속도와 정확도가 중요하다는 생각에
애초에 처음부터 기초자산 유형을 파악해서 컬럼에 저장해 놓는게 성능 면에서 훨씬 좋을 거 같았습니다.
또한 아래와 같이, 이전부터 TickerSymbol Entity에 기초자산에 해당하는 티커 심볼과 유형을 저장해놓았기 때문에
이 내용을 배치 서비스에서 상품을 파싱해올 때 활용하였습니다.
| ticker_symbol_id | equity_name | ticker_symbol | underlying_asset_type | ... |
| 1 | Apple Inc. | AAPL | STOCK | |
| 169 | S&P500 Index | ^GSPC | INDEX | |
| 1210 | 삼성전자 | 005930.KS | STOCK |
그래서 우선은 Product Entity에 아래와 같이 유형을 파악할 수 있는 필드를 추가했습니다. (상품 서비스, 배치 서비스)
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Product extends BaseEntity {
...
@NotNull
@Enumerated(STRING)
private UnderlyingAssetType underlyingAssetType;
...
}/**
* 기초자산 유형
*/
public enum UnderlyingAssetType {
/**
* 주가 지수
*/
INDEX,
/**
* 종목
*/
STOCK,
/**
* 혼합
*/
MIX
}
또한 배치 서비스에는 아래와 같이 어떠한 유형의 기초자산들을 가진 상품인지 판별하고
트랜잭션 처리를 하는 코드를 추가해주었습니다.
@Service
@RequiredArgsConstructor
@Slf4j
public class ParsingExcelService {
...
@Transactional
public void parsingExcel() throws IOException, InvalidFormatException {
...
try (InputStream inputStream = new FileInputStream(file)) {
...
int cntForSleep = 1;
for (int r = 1; r < rows; r++) {
...
if (prospectusLink != null) {
Document doc = parsingProspectusService.fetchDocument(prospectusLink);
// 정정신고한 투자설명서라면 알림
parsingProspectusService.findIsCorrectionReport(dCell.getStringCellValue(), prospectusLink, doc);
parsingProspectusService.findVolatilitiesList(doc);
log.info(r+1 + " - 변동성:" + parsingProspectusService.findVolatilities(findProductSession(dCell.getStringCellValue()),doc));
// 기초자산 db
String[] equities = eCell.getStringCellValue().split("<br/>");
int equityCount = equities.length, productUnderlyingAssetScore = 0;
for (String equity : equities) {
Optional<TickerSymbol> tickerSymbol = tickerSymbolRepository.findTickerSymbolByEquityName(equity);
if (tickerSymbol.isPresent() && !Objects.equals(tickerSymbol.get().getTickerSymbol(), "NEED_TO_CHECK")) {
if (tickerSymbol.get().getUnderlyingAssetType().equals(UnderlyingAssetType.INDEX))
productUnderlyingAssetScore++;
} else {
productUnderlyingAssetScore = -1;
log.warn(dCell + " : " + "기초자산 " +equity + " 에 대해서 Ticker가 존재하지 않음 업데이트 필요");
NewTickerMessage newTickerMessage = NewTickerMessage.builder()
.productName(dCell.getStringCellValue())
.equity(equity)
.build();
newTickerMessageSender.send("new-ticker-alert", newTickerMessage);
}
}
if (productUnderlyingAssetScore == -1) continue;
// 기초자산들이 정상적으로 존재하는 경우에 동작
Product product = Product.builder()
.issuer(bCell.getStringCellValue())
.name(dCell.getStringCellValue())
.issueNumber(Integer.valueOf(findIssueNumber(dCell.getStringCellValue())))
.equities(eCell.getStringCellValue().replace("<br/>", " / "))
.equityCount(eCell.getStringCellValue().split("<br/>").length)
.issuedDate(convertToLocalDate(fCell.getStringCellValue()))
.maturityEvaluationDate(parsingProspectusService.findMaturityEvaluationDate(bCell.getStringCellValue(), findProductSession(dCell.getStringCellValue()), doc))
.maturityEvaluationDateType(parsingProspectusService.findMaturityEvaluationDateCount(bCell.getStringCellValue(), findProductSession(dCell.getStringCellValue()), doc))
.maturityDate(convertToLocalDate(gCell.getStringCellValue()))
.yieldIfConditionsMet(BigDecimal.valueOf(hCell.getNumericCellValue()))
.maximumLossRate(BigDecimal.valueOf(iCell.getNumericCellValue()))
.subscriptionStartDate(convertToLocalDate(jCell.getStringCellValue()))
.subscriptionEndDate(convertToLocalDate(kCell.getStringCellValue()))
.productFullInfo(lCell.getStringCellValue())
.productInfo(findProductInfo(lCell.getStringCellValue()))
.link(nCell.getStringCellValue())
.remarks(pCell.getStringCellValue())
.knockIn(findKnockIn(lCell.getStringCellValue()))
.summaryInvestmentProspectusLink(prospectusLink)
.earlyRepaymentEvaluationDates(Optional.ofNullable(
parsingProspectusService.findEarlyRepaymentEvaluationDates(
findProductSession(dCell.getStringCellValue()),
doc
)
).map(dates -> String.join(", ", dates))
.orElse(null)
)
.volatilites(parsingProspectusService.findVolatilities(findProductSession(dCell.getStringCellValue()), doc).get(0))
.initialBasePriceEvaluationDate(parsingProspectusService.findInitialBasePriceEvaluationDate(bCell.getStringCellValue(), findProductSession(dCell.getStringCellValue()), doc))
.productType(findProductType(bCell.getStringCellValue(), lCell.getStringCellValue()))
.underlyingAssetType(checkUnderlyingAssetType(productUnderlyingAssetScore, equityCount))
.productState(ProductState.ACTIVE)
.build();
productRepository.save(product);
...
} else {
...
}
cntForSleep++;
}
} catch (IOException | InvalidFormatException e) {
log.error("Error processing Excel file: ", e);
}
}
...
private UnderlyingAssetType checkUnderlyingAssetType(int score, int underlyingAssetCount) {
/**
* 각 기초자산에 대해서 지수형(INDEX)이면 score += 1
* TickerSymbol에 존재하지 않는 기초자산이라면 score = -1로 설정했음
*
* 개수 1 2 3
* 유형
* INDEX 1 2 3
* STOCK 0 0 0
* MIX x 1 1or2
*/
if (score == underlyingAssetCount)
return UnderlyingAssetType.INDEX;
if (score == 0)
return UnderlyingAssetType.STOCK;
if ((score != -1) && (score < underlyingAssetCount))
return UnderlyingAssetType.MIX;
return UnderlyingAssetType.NEED_TO_CHECK;
}
}
그리고 상품 서비스에 작성했던 기존의 StackOverFlow 오류가 발생한
상품 상세 검색 코드는 아래와 같이 간단하게 바뀌었습니다.
private BooleanExpression equityTypeEq(UnderlyingAssetType type) {
return type != null ? product.underlyingAssetType.eq(type) : null;
}
이후 nGrinder를 활용하여 개발 서버에 올라가 있는 API에 대해서 성능 테스트를 진행해보았습니다.
주가지수형 상품 상세 검색 API에 대한 스크립트
import static net.grinder.script.Grinder.grinder
import static org.junit.Assert.*
import static org.hamcrest.Matchers.*
import net.grinder.script.GTest
import net.grinder.script.Grinder
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
import org.junit.Before
import org.junit.BeforeClass
import org.junit.Test
import org.junit.runner.RunWith
import org.ngrinder.http.HTTPRequest
import org.ngrinder.http.HTTPRequestControl
import org.ngrinder.http.HTTPResponse
@RunWith(GrinderRunner)
class ProductSearchTest {
public static GTest test;
public static HTTPRequest request;
public static Map<String, String> headers = [:];
public static Map<String, Object> params = [:];
public static String accessToken;
public static String serverBaseUrl;
@BeforeProcess
public static void beforeProcess() {
HTTPRequestControl.setConnectionTimeout(300000);
test = new GTest(1, "test");
request = new HTTPRequest();
grinder.logger.info("before process.");
}
@BeforeThread
public void beforeThread() {
test.record(this, "test");
grinder.statistics.delayReports = true;
grinder.logger.info("before thread.");
}
@Before
public void before() {
accessToken = System.getenv("ACCESS_TOKEN");
serverBaseUrl = System.getenv("SERVER_BASE_URL");
headers = ["Authorization": "Bearer " + accessToken];
request.setHeaders(headers);
grinder.logger.info("before. init headers");
}
@Test
public void test() {
params = [
equityNames: null,
equityCount: null,
issuer: null,
maxKnockIn: null,
minYieldIfConditionsMet: null,
initialRedemptionBarrier: null,
maturityRedemptionBarrier: null,
subscriptionPeriod: null,
redemptionInterval: null,
equityType: "INDEX",
type: null,
subscriptionStartDate: null,
subscriptionEndDate: null
]
HTTPResponse response = request.POST(serverBaseUrl + "/api/product-service/v1/product/search?page=0&size=20", params);
if (response.statusCode == 301 || response.statusCode == 302) {
grinder.logger.warn("Warning. The response may not be correct. The response code was {}.", response.statusCode);
} else {
assertThat(response.statusCode, is(200));
}
}
}
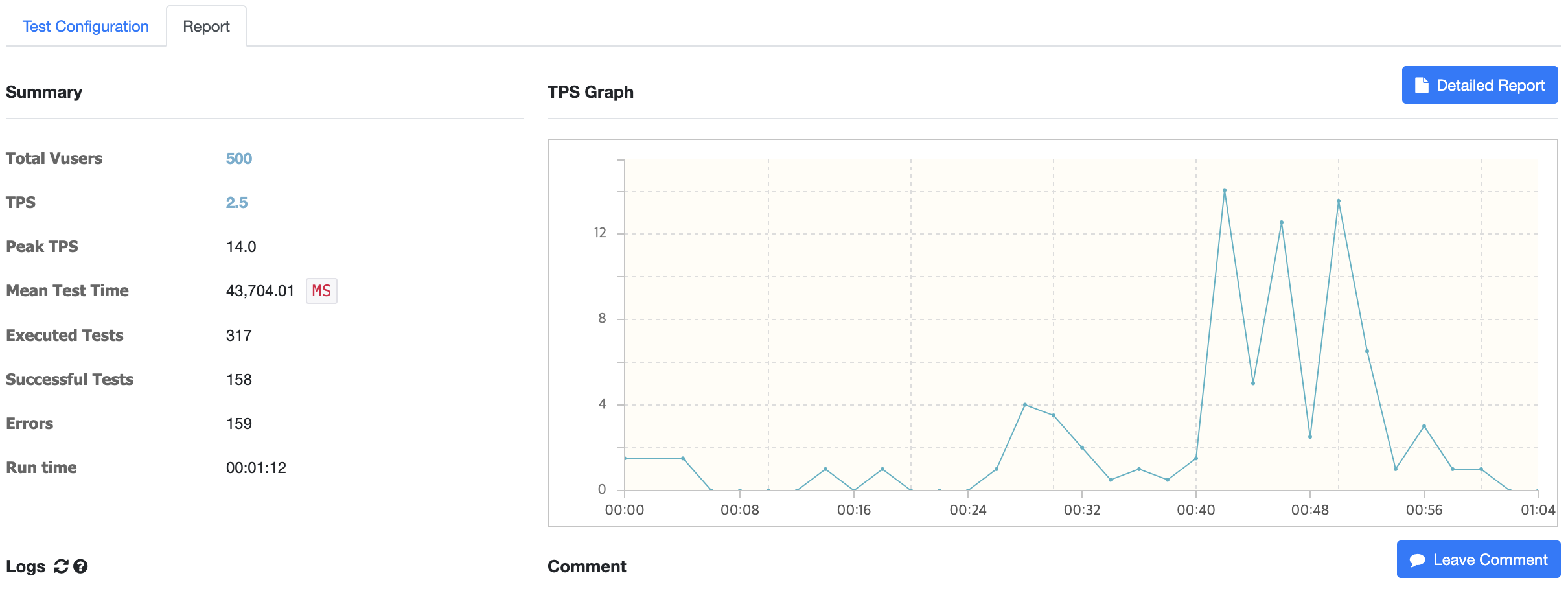
결과: 코드 수정 전
테스트 시간 5분을 다 채우지도 못하고 1분쯤에 오류가 너무 많아서 중단됐었습니다.
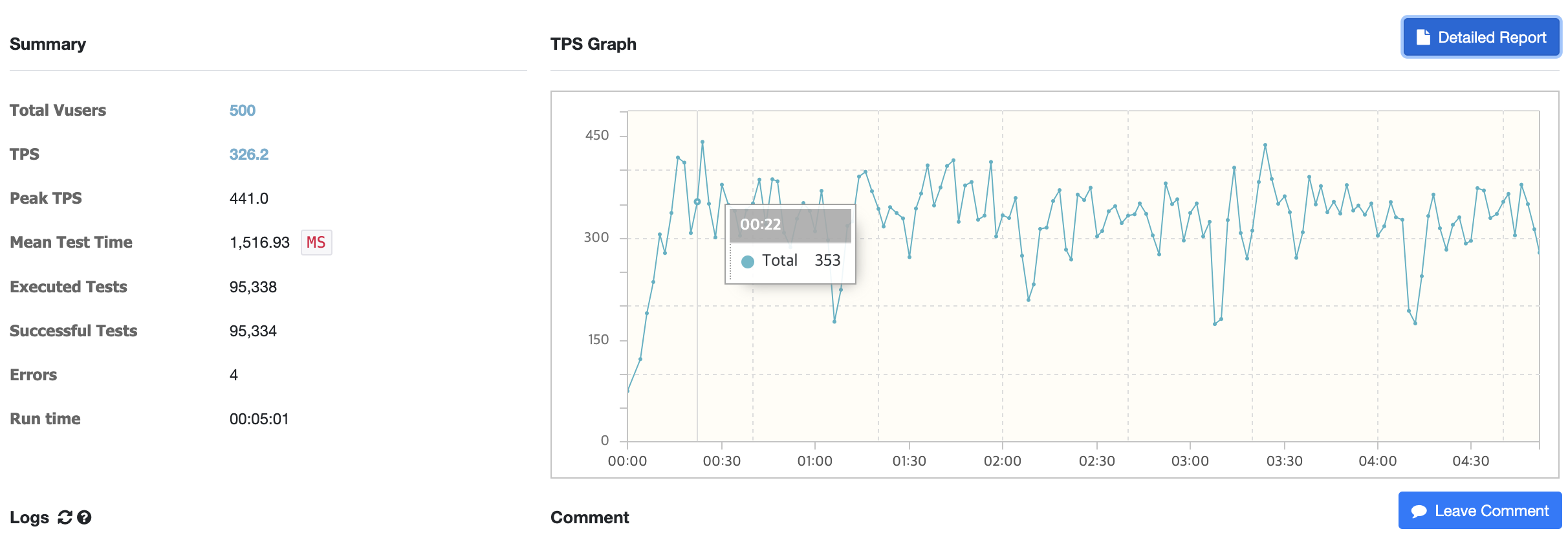
결과: 코드 수정 후
확실히 평균 TPS가 326.2가 나오면서 안정성과 성능 면에서 훨씬 더 나은 것을 확인할 수 있었습니다.
'SpringBoot' 카테고리의 다른 글
| Redis 캐싱을 사용하여, 일일 조회수와 좋아요 증감 수를 반영한 일일 HOT 상품 목록 조회 기능 개발 (0) | 2024.12.19 |
|---|---|
| Spring Boot와 Kafka 테스트: Embedded Kafka로 상품 좋아요 메시지 검증하기 (1) | 2024.10.13 |
| MSA) 서비스 별 각 인스턴스에서 애플리케이션을 Docker 컨테이너화 후, 발생한 Eureka Client 간의 통신 문제 (0) | 2024.07.09 |
| MSA) Spring Cloud 기반의 MSA 구조에서 Swagger 통합하기 + FastAPI의 Swagger까지 (0) | 2024.06.17 |
| MSA) Spring Cloud Eureka에 FastAPI 서버를 Client로 등록하기 (0) | 2024.06.01 |